from pathlib import Path
from joshpy.jobs import JobConfig, SweepConfig, ConfigSweepParameter
from joshpy.sweep import SweepManager
from joshpy.cli import JoshCLI
from joshpy.jar import JarMode
from joshpy.catalog import ProjectCatalog
SOURCE_PATH = Path("../../examples/tutorial_sweep.josh")
TEMPLATE_PATH = Path("../../examples/templates/sweep_config.jshc.j2")
cli = JoshCLI(josh_jar=JarMode.DEV)
catalog = ProjectCatalog("sweep_catalog.duckdb")Multi-Session Sweeps
Track parameter sweeps across sessions with ProjectCatalog
Overview
When running parameter sweeps across multiple sessions – a baseline sweep today, a wider sweep tomorrow – the ProjectCatalog keeps track of what’s been run and prevents duplicate work.
Unlike ad-hoc iteration where runs accumulate in a single registry, each sweep typically gets its own registry. The catalog indexes them all.
Setup
Session 1: Baseline Sweep
A focused sweep over a narrow parameter range:
config_baseline = JobConfig(
template_path=TEMPLATE_PATH,
source_path=SOURCE_PATH,
simulation="Main",
replicates=2,
sweep=SweepConfig(
config_parameters=[
ConfigSweepParameter(name="maxGrowth", values=[25, 50, 75]),
],
),
)
manager = (
SweepManager.builder(config_baseline)
.with_registry("sweep_baseline.duckdb", experiment_name="baseline_sweep")
.with_cli(cli)
.with_catalog(catalog, experiment_name="baseline_sweep")
.build()
)
try:
results = manager.run()
print(f"Baseline sweep: {results.succeeded} succeeded, {results.failed} failed")
if results.failed > 0:
raise RuntimeError("Sweep failed")
manager.load_results()
finally:
manager.cleanup()
manager.close()Running 3 jobs (6 total replicates)
[1/3] Running (local): {'maxGrowth': 25}
[OK] Completed successfully
[2/3] Running (local): {'maxGrowth': 50}
[OK] Completed successfully
[3/3] Running (local): {'maxGrowth': 75}
[OK] Completed successfully
Completed: 3 succeeded, 0 failed
Baseline sweep: 3 succeeded, 0 failed
Loading patch results from: /tmp/tutorial_sweep_{maxGrowth}_{replicate}.csv
Loaded 1463 rows from tutorial_sweep_25_0.csv
Loaded 1463 rows from tutorial_sweep_25_1.csv
Loaded 1463 rows from tutorial_sweep_50_0.csv
Loaded 1463 rows from tutorial_sweep_50_1.csv
Loaded 1463 rows from tutorial_sweep_75_0.csv
Loaded 1463 rows from tutorial_sweep_75_1.csv
Results:
Jobs in sweep: 3
Jobs with results loaded: 3
Total rows loaded: 8778
8778Analyze within this sweep
Each sweep is self-contained – analyze it with its own registry:
from joshpy.registry import RunRegistry
from joshpy.diagnostics import SimulationDiagnostics
registry = RunRegistry("sweep_baseline.duckdb")
diag = SimulationDiagnostics(registry)
diag.plot_comparison("averageHeight", group_by="maxGrowth",
title="Baseline Sweep")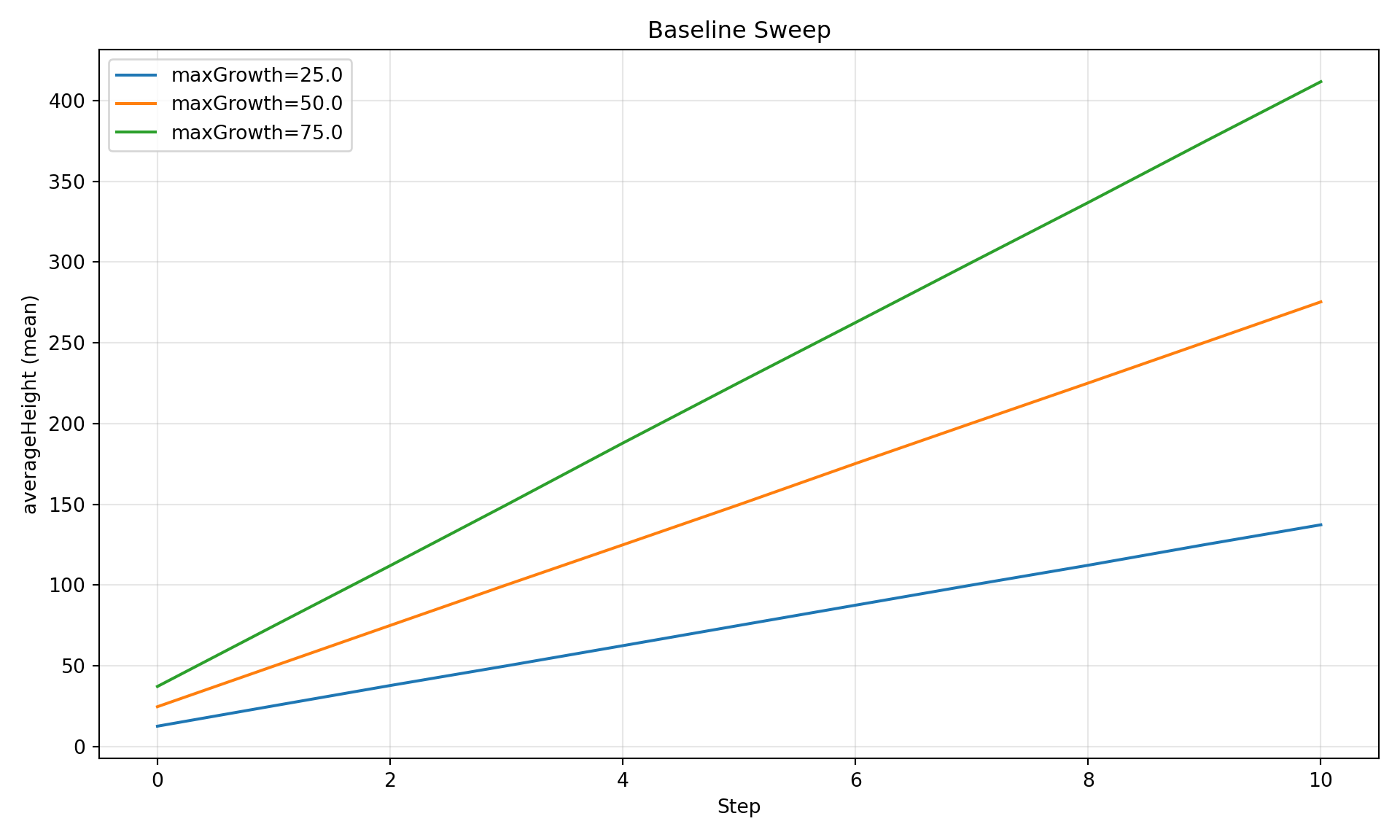
registry.close()Session 2: Wider Sweep
Based on the baseline results, you decide to explore higher values:
config_wide = JobConfig(
template_path=TEMPLATE_PATH,
source_path=SOURCE_PATH,
simulation="Main",
replicates=2,
sweep=SweepConfig(
config_parameters=[
ConfigSweepParameter(name="maxGrowth", values=[100, 150, 200]),
],
),
)
manager = (
SweepManager.builder(config_wide)
.with_registry("sweep_wide.duckdb", experiment_name="wide_sweep")
.with_cli(cli)
.with_catalog(catalog, experiment_name="wide_sweep")
.build()
)
try:
results = manager.run()
print(f"Wide sweep: {results.succeeded} succeeded, {results.failed} failed")
if results.failed > 0:
raise RuntimeError("Sweep failed")
manager.load_results()
finally:
manager.cleanup()
manager.close()Running 3 jobs (6 total replicates)
[1/3] Running (local): {'maxGrowth': 100}
[OK] Completed successfully
[2/3] Running (local): {'maxGrowth': 150}
[OK] Completed successfully
[3/3] Running (local): {'maxGrowth': 200}
[OK] Completed successfully
Completed: 3 succeeded, 0 failed
Wide sweep: 3 succeeded, 0 failed
Loading patch results from: /tmp/tutorial_sweep_{maxGrowth}_{replicate}.csv
Loaded 1463 rows from tutorial_sweep_100_0.csv
Loaded 1463 rows from tutorial_sweep_100_1.csv
Loaded 1463 rows from tutorial_sweep_150_0.csv
Loaded 1463 rows from tutorial_sweep_150_1.csv
Loaded 1463 rows from tutorial_sweep_200_0.csv
Loaded 1463 rows from tutorial_sweep_200_1.csv
Results:
Jobs in sweep: 3
Jobs with results loaded: 3
Total rows loaded: 8778
8778Session 3: Recall What’s Been Done
The catalog tells you what sweeps exist across all sessions:
catalog = ProjectCatalog("sweep_catalog.duckdb")
experiments = catalog.list_experiments()
print(f"Registered experiments: {len(experiments)}\n")Registered experiments: 2for exp in experiments:
print(f" {exp.name}")
print(f" status: {exp.status}")
print(f" registry: {exp.registry_path}")
print() wide_sweep
status: completed
registry: sweep_wide.duckdb
baseline_sweep
status: completed
registry: sweep_baseline.duckdbCheck before re-running
existing = catalog.find_experiment(config_baseline)
if existing:
print(f"Already run: '{existing.name}'")
print(f" Results at: {existing.registry_path}")
print(f" Status: {existing.status}")
else:
print("Not yet run")Already run: 'wide_sweep'
Results at: sweep_wide.duckdb
Status: completedOpen a past registry
# Find the wide sweep and open its registry
wide_exp = [e for e in experiments if e.name == "wide_sweep"][0]
registry = RunRegistry(wide_exp.registry_path)
diag = SimulationDiagnostics(registry)
diag.plot_comparison("averageHeight", group_by="maxGrowth",
title="Wide Sweep (recalled from catalog)")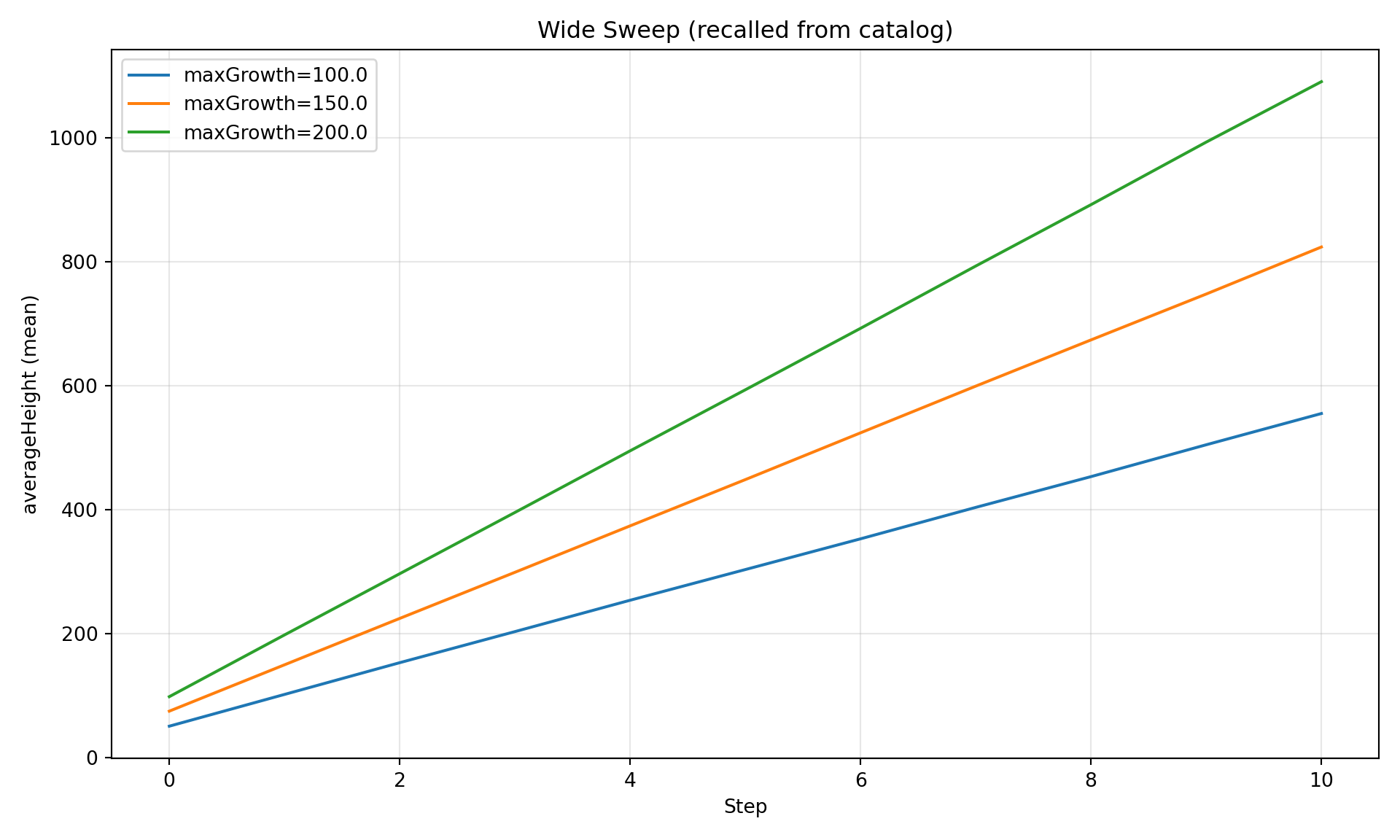
registry.close()Key Concepts
TipSweeping over data files?
If your sweep varies external data (e.g., climate scenarios) rather than config parameters, see Sweeping Over External Data. GridSpec’s variant_sweep() generates the sweep parameters from your YAML manifest — no manual FileSweepParameter construction needed.
One registry per sweep
Each sweep produces a self-contained registry. Analysis happens within that registry using group_by="maxGrowth" (or whatever parameter was swept). You don’t need cross-experiment queries for sweep analysis.
Catalog as bookkeeper
The catalog answers project-level questions:
list_experiments()– What sweeps have been run?find_experiment(config)– Has this exact sweep been run before?exp.registry_path– Where are the results?
When to use ad-hoc vs sweep multi-session
| Pattern | Multiple runs → same registry | Multiple sweeps → separate registries |
|---|---|---|
| Use case | Exploratory tinkering | Systematic parameter exploration |
| Comparison | group_by="label" |
group_by="maxGrowth" |
| Catalog role | Find the iteration registry | Index all sweep registries |
| Tutorial | Multi-Session Experiments | This page |
Next Steps
- Multi-Session Experiments – Ad-hoc iteration across sessions
- SweepManager Workflow – In-depth sweep tutorial
- Architecture – How all abstractions fit together
Cleanup
catalog.close()